![]()
[Dec 15, 2025] Databricks-Certified-Professional-Data-Engineer PDF Dumps is essential on your Databricks-Certified-Professional-Data-Engineer Exam Questions Certain Success!
Databricks-Certified-Professional-Data-Engineer PDF Questions - Perfect Prospect To Go With Databricks-Certified-Professional-Data-Engineer Practice Exam
Databricks-Certified-Professional-Data-Engineer exam consists of multiple-choice questions and hands-on, real-world scenarios that test the candidate's ability to design, build, and deploy data pipelines on Databricks. Databricks-Certified-Professional-Data-Engineer exam covers various topics, including data engineering concepts, Databricks architecture, data processing using Spark, and data integration with other systems. Databricks Certified Professional Data Engineer Exam certification program provides a comprehensive learning experience that prepares candidates to become skilled data engineers and provides them with a competitive edge in the job market.
Databricks Certified Professional Data Engineer exam consists of a set of performance-based tasks that test the candidate's ability to apply their knowledge and skills to real-world scenarios. Databricks-Certified-Professional-Data-Engineer exam is conducted online and can be taken from anywhere in the world. Databricks-Certified-Professional-Data-Engineer exam is timed and candidates have to complete the tasks within the given time frame. Databricks-Certified-Professional-Data-Engineer exam is designed in such a way that it assesses the candidate's ability to work with Databricks Unified Analytics Platform and solve complex data engineering problems.
NEW QUESTION # 73
You are trying to create an object by joining two tables that and it is accessible to data scientist's team, so it does not get dropped if the cluster restarts or if the notebook is detached. What type of object are you trying to create?
- A. External view
- B. Global Temporary view
- C. Temporary view
- D. View
- E. Global Temporary view with cache option
Answer: D
Explanation:
Explanation
Answer is View, A view can be used to join multiple tables but also persist into meta stores so others can accesses it
NEW QUESTION # 74
What is the main difference between the bronze layer and silver layer in a medallion architecture?
- A. Silver may contain aggregated data
- B. Bad data is filtered in Bronze, silver is a copy of bronze data
- C. Duplicates are removed in bronze, schema is applied in silver
- D. Bronze is raw copy of ingested data, silver contains data with production schema and optimized for ELT/ETL throughput
Answer: D
Explanation:
Explanation
Medallion Architecture - Databricks
Exam focus: Please review the below image and understand the role of each layer(bronze, silver, gold) in medallion architecture, you will see varying questions targeting each layer and its purpose.
Sorry I had to add the watermark some people in Udemy are copying my content.
A diagram of a house Description automatically generated with low confidence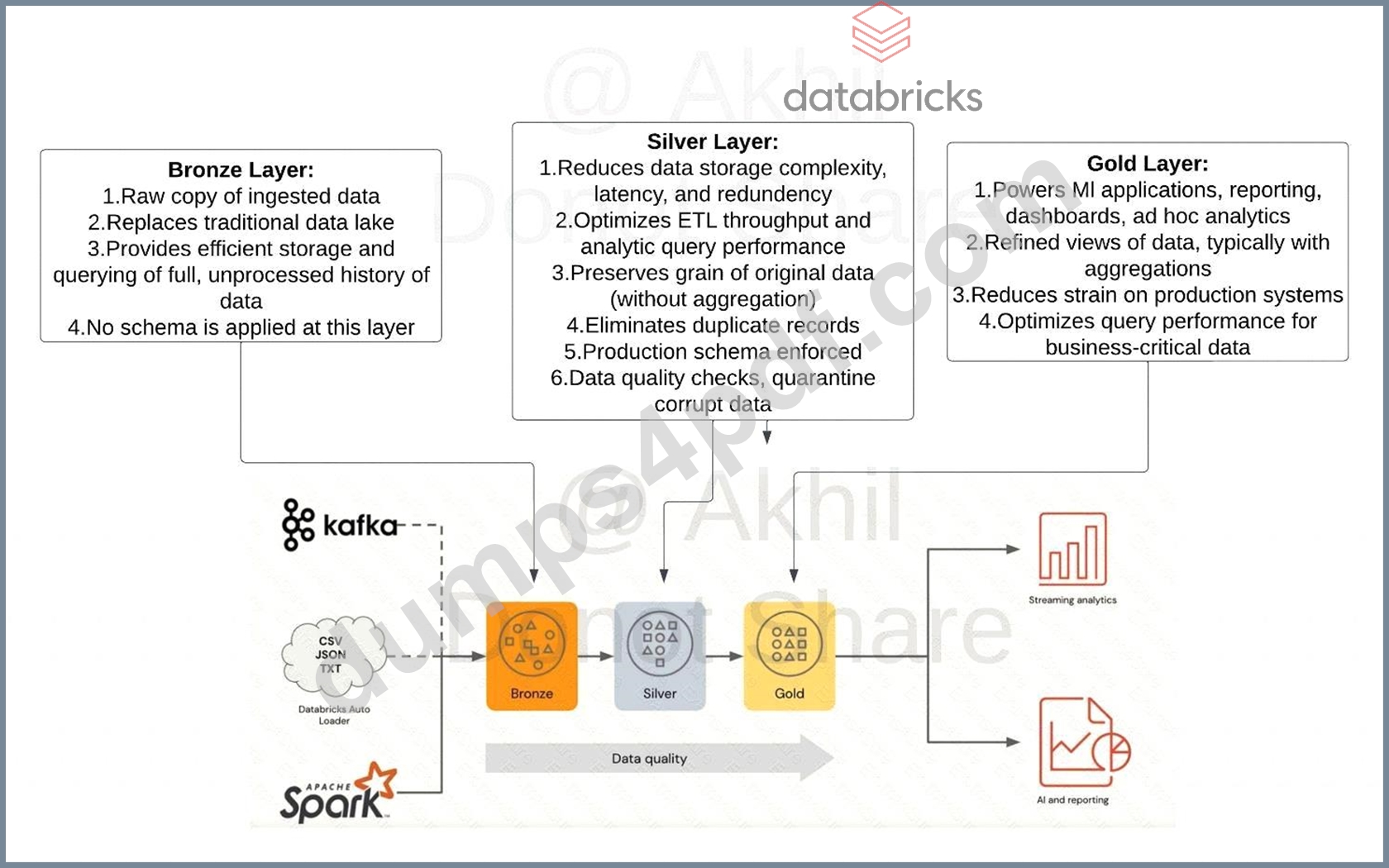
NEW QUESTION # 75
The data engineering team maintains a table of aggregate statistics through batch nightly updates. This includes total sales for the previous day alongside totals and averages for a variety of time periods including the 7 previous days, year-to-date, and quarter-to-date. This table is namedstore_saies_summaryand the schema is as follows:
The tabledaily_store_salescontains all the information needed to updatestore_sales_summary. The schema for this table is:
store_id INT, sales_date DATE, total_sales FLOAT
Ifdaily_store_salesis implemented as a Type 1 table and the column might be adjusted after manual data auditing, which approach is the safest to generate accurate reports in thestore_sales_summarytable?
- A. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and use upsert logic to update results in the store_sales_summary table.
- B. Implement the appropriate aggregate logic as a Structured Streaming read against the daily_store_sales table and use upsert logic to update results in the store_sales_summary table.
- C. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and append new rows nightly to the store_sales_summary table.
- D. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and overwrite the store_sales_summary table with each Update.
- E. Use Structured Streaming to subscribe to the change data feed for daily_store_sales and apply changes to the aggregates in the store_sales_summary table with each update.
Answer: E
Explanation:
Explanation
The daily_store_sales table contains all the information needed to update store_sales_summary. The schema of the table is:
store_id INT, sales_date DATE, total_sales FLOAT
The daily_store_sales table is implemented as a Type 1 table, which means that old values are overwritten by new values and no history is maintained. The total_sales column might be adjusted after manual data auditing, which means that the data in the table may change over time.
The safest approach to generate accurate reports in the store_sales_summary table is to use Structured Streaming to subscribe to the change data feed for daily_store_sales and apply changes to the aggregates in the store_sales_summary table with each update. Structured Streaming is a scalable and fault-tolerant stream processing engine built on Spark SQL. Structured Streaming allows processing data streams as if they were tables or DataFrames, using familiar operations such as select, filter, groupBy, or join. Structured Streaming also supports output modes that specify how to write the results of a streaming query to a sink, such as append, update, or complete. Structured Streaming can handle both streaming and batch data sources in a unified manner.
The change data feed is a feature of Delta Lake that provides structured streaming sources that can subscribe to changes made to a Delta Lake table. The change data feed captures both data changes and schema changes as ordered events that can be processed by downstream applications or services. The change data feed can be configured with different options, such as starting from a specific version or timestamp, filtering by operation type or partition values, or excluding no-op changes.
By using Structured Streaming to subscribe to the change data feed for daily_store_sales, one can capture and process any changes made to the total_sales column due to manual data auditing. By applying these changes to the aggregates in the store_sales_summary table with each update, one can ensure that the reports are always consistent and accurate with the latest data. Verified References: [Databricks Certified Data Engineer Professional], under "Spark Core" section; Databricks Documentation, under "Structured Streaming" section; Databricks Documentation, under "Delta Change Data Feed" section.
NEW QUESTION # 76
The security team is exploring whether or not the Databricks secrets module can be leveraged for connecting to an external database.
After testing the code with all Python variables being defined with strings, they upload the password to the secrets module and configure the correct permissions for the currently active user. They then modify their code to the following (leaving all other variables unchanged).
Which statement describes what will happen when the above code is executed?
- A. An interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the password will be printed in plain text.
- B. The connection to the external table will succeed; the string value of password will be printed in plain text.
- C. The connection to the external table will fail; the string "redacted" will be printed.
- D. An interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the encoded password will be saved to DBFS.
- E. The connection to the external table will succeed; the string "redacted" will be printed.
Answer: E
Explanation:
This is the correct answer because the code is using the dbutils.secrets.get method to retrieve the password from the secrets module and store it in a variable. The secrets module allows users to securely store and access sensitive information such as passwords, tokens, or API keys. The connection to the external table will succeed because the password variable will contain the actual password value. However, when printing the password variable, the string "redacted" will be displayed instead of the plain text password, as a security measure to prevent exposing sensitive information in notebooks. Verified References: [Databricks Certified Data Engineer Professional], under "Security & Governance" section; Databricks Documentation, under
"Secrets" section.
NEW QUESTION # 77
Which of the statement is correct about the cluster pools?
- A. Cluster pools allow you to perform load balancing
- B. Cluster pools allow you to create a cluster
- C. Cluster pools are used to share resources among multiple teams
- D. Cluster pools allow you to save time when starting a new cluster
- E. Cluster pools allow you to have all the nodes in the cluster from single physical server rack
Answer: D
NEW QUESTION # 78
The data architect has mandated that all tables in the Lakehouse should be configured as external (also known as "unmanaged") Delta Lake tables.
Which approach will ensure that this requirement is met?
- A. When tables are created, make sure that the EXTERNAL keyword is used in the CREATE TABLE statement.
- B. When configuring an external data warehouse for all table storage, leverage Databricks for all ELT.
- C. When data is saved to a table, make sure that a full file path is specified alongside the Delta format.
- D. When a database is being created, make sure that the LOCATION keyword is used.
- E. When the workspace is being configured, make sure that external cloud object storage has been mounted.
Answer: A
Explanation:
To create an external or unmanaged Delta Lake table, you need to use the EXTERNAL keyword in the CREATE TABLE statement. This indicates that the table is not managed by the catalog and the data files are not deleted when the table is dropped. You also need to provide a LOCATION clause to specify the path where the data files are stored. For example:
CREATE EXTERNAL TABLE events ( date DATE, eventId STRING, eventType STRING, data STRING) USING DELTA LOCATION '/mnt/delta/events'; This creates an external Delta Lake table named events that references the data files in the '/mnt/delta/events' path. If you drop this table, the data files will remain intact and you can recreate the table with the same statement.
Reference:
https://docs.databricks.com/delta/delta-batch.html#create-a-table
https://docs.databricks.com/delta/delta-batch.html#drop-a-table
NEW QUESTION # 79
All records from an Apache Kafka producer are being ingested into a single Delta Lake table with the following schema:
key BINARY, value BINARY, topic STRING, partition LONG, offset LONG, timestamp LONG There are 5 unique topics being ingested. Only the "registration" topic contains Personal Identifiable Information (PII). The company wishes to restrict access to PII. The company also wishes to only retain records containing PII in this table for 14 days after initial ingestion. However, for non-PII information, it would like to retain these records indefinitely.
Which of the following solutions meets the requirements?
- A. Separate object storage containers should be specified based on the partition field, allowing isolation at the storage level.
- B. Data should be partitioned by the registration field, allowing ACLs and delete statements to be set for the PII directory.
- C. Because the value field is stored as binary data, this information is not considered PII and no special precautions should be taken.
- D. All data should be deleted biweekly; Delta Lake's time travel functionality should be leveraged to maintain a history of non-PII information.
- E. Data should be partitioned by the topic field, allowing ACLs and delete statements to leverage partition boundaries.
Answer: B
Explanation:
Partitioning the data by the topic field allows the company to apply different access control policies and retention policies for different topics. For example, the company can use the Table Access Control feature to grant or revoke permissions to the registration topic based on user roles or groups. The company can also use the DELETE command to remove records from the registration topic that are older than 14 days, while keeping the records from other topics indefinitely. Partitioning by the topic field also improves the performance of queries that filter by the topic field, as they can skip reading irrelevant partitions. References:
* Table Access Control: https://docs.databricks.com/security/access-control/table-acls/index.html
* DELETE: https://docs.databricks.com/delta/delta-update.html#delete-from-a-table
NEW QUESTION # 80
Which statement describes integration testing?
- A. Requires an automated testing framework
- B. Requires manual intervention
- C. Validates behavior of individual elements of your application
- D. Validates an application use case
- E. Validates interactions between subsystems of your application
Answer: E
Explanation:
This is the correct answer because it describes integration testing. Integration testing is a type of testing that validates interactions between subsystems of your application, such as modules, components, or services. Integration testing ensures that the subsystems work together as expected and produce the correct outputs or results. Integration testing can be done at different levels of granularity, such as component integration testing, system integration testing, or end-to-end testing. Integration testing can help detect errors or bugs that may not be found by unit testing, which only validates behavior of individual elements of your application. Verified Reference: [Databricks Certified Data Engineer Professional], under "Testing" section; Databricks Documentation, under "Integration testing" section.
NEW QUESTION # 81
You are working to set up two notebooks to run on a schedule, the second notebook is dependent on the first notebook but both notebooks need different types of compute to run in an optimal fashion, what is the best way to set up these notebooks as jobs?
- A. Each task can use different cluster, add these two notebooks as two tasks in a single job with linear dependency and modify the cluster as needed for each of the tasks
- B. Use DELTA LIVE PIPELINES instead of notebook tasks
- C. Use a single job to setup both notebooks as individual tasks, but use the cluster API to setup the second cluster before the start of second task
- D. A Job can only use single cluster, setup job for each notebook and use job dependency to link both jobs together
- E. Use a very large cluster to run both the tasks in a single job
Answer: A
Explanation:
Explanation
Tasks in Jobs support different clusters for each task in the same job.
NEW QUESTION # 82
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
MERGE INTO customers
USING (
SELECT updates.customer_id as merge_ey, updates .*
FROM updates
UNION ALL
SELECT NULL as merge_key, updates .*
FROM updates JOIN customers
ON updates.customer_id = customers.customer_id
WHERE customers.current = true AND updates.address <> customers.address ) staged_updates ON customers.customer_id = mergekey WHEN MATCHED AND customers. current = true AND customers.address <> staged_updates.address THEN UPDATE SET current = false, end_date = staged_updates.effective_date WHEN NOT MATCHED THEN INSERT (customer_id, address, current, effective_date, end_date) VALUES (staged_updates.customer_id, staged_updates.address, true, staged_updates.effective_date, null) Which statement describes this implementation?
- A. The customers table is implemented as a Type 2 table; old values are maintained but marked as no longer current and new values are inserted.
- B. The customers table is implemented as a Type 0 table; all writes are append only with no changes to existing values.
- C. The customers table is implemented as a Type 2 table; old values are overwritten and new customers are appended.
- D. The customers table is implemented as a Type 1 table; old values are overwritten by new values and no history is maintained.
Answer: A
Explanation:
The provided MERGE statement is a classic implementation of a Type 2 SCD in a data warehousing context.
In this approach, historical data is preserved by keeping old records (marking them as not current) and adding new records for changes. Specifically, when a match is found and there's a change in the address, the existing record in the customers table is updated to mark it as no longer current (current = false), and an end date is assigned (end_date = staged_updates.effective_date). A new record for the customer is then inserted with the updated information, marked as current. This method ensures that the full history of changes to customer information is maintained in the table, allowing for time-based analysis of customer data.References:
Databricks documentation on implementing SCDs using Delta Lake and the MERGE statement (https://docs.databricks.com/delta/delta-update.html#upsert-into-a-table-using-merge).
NEW QUESTION # 83
You are currently working on a notebook that will populate a reporting table for downstream process consumption, this process needs to run on a schedule every hour, what type of cluster are you going to use to set up this job?
- A. Use Azure VM to read and write delta tables in Python
- B. The job cluster is best suited for this purpose.
- C. Use delta live table pipeline to run in continuous mode
- D. Since it's just a single job and we need to run every hour, we can use an all-purpose cluster
Answer: B
Explanation:
Explanation
The answer is, The Job cluster is best suited for this purpose.
Since you don't need to interact with the notebook during the execution especially when it's a scheduled job, job cluster makes sense. Using an all-purpose cluster can be twice as expensive as a job cluster.
FYI,
When you run a job scheduler with option of creating a new cluster when the job is complete it terminates the cluster. You cannot restart a job cluster.
NEW QUESTION # 84
What is the purpose of the bronze layer in a Multi-hop Medallion architecture?
- A. Reduces data storage by compressing the data
- B. Powers ML applications
- C. Data quality checks, corrupt data quarantined
- D. Copy of raw data, easy to query and ingest data for downstream processes.
- E. Contain aggregated data that is to be consumed into Silver
Answer: D
Explanation:
Explanation
The answer is, copy of raw data, easy to query and ingest data for downstream processes, Medallion Architecture - Databricks Here are the typical role of Bronze Layer in a medallion architecture.
Bronze Layer:
1. Raw copy of ingested data
2. Replaces traditional data lake
3. Provides efficient storage and querying of full, unprocessed history of data
4. No schema is applied at this layer
Exam focus: Please review the below image and understand the role of each layer(bronze, silver, gold) in medallion architecture, you will see varying questions targeting each layer and its purpose.
Sorry I had to add the watermark some people in Udemy are copying my content.
NEW QUESTION # 85
A junior data engineer on your team has implemented the following code block.
The viewnew_eventscontains a batch of records with the same schema as theeventsDelta table.
Theevent_idfield serves as a unique key for this table.
When this query is executed, what will happen with new records that have the sameevent_idas an existing record?
- A. They are deleted.
- B. They are merged.
- C. They are updated.
- D. They are inserted.
- E. They are ignored.
Answer: E
Explanation:
This is the correct answer because it describes what will happen with new records that have the same event_id as an existing record when the query is executed. The query uses the INSERT INTO command to append new records from the view new_events to the table events. However, the INSERT INTO command does not check for duplicate values in the primary key column (event_id) and does not perform any update or delete operations on existing records. Therefore, if there are new records that have the same event_id as an existing record, they will be ignored and not inserted into the table events. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Append data using INSERT INTO" section.
"If none of the WHEN MATCHED conditions evaluate to true for a source and target row pair that matches the merge_condition, then the target row is left unchanged."https://docs.databricks.com/en/sql/language-manual/delta-merge-into.html#:~:text=If%20none%20o
NEW QUESTION # 86
Which statement describes Delta Lake Auto Compaction?
- A. Data is queued in a messaging bus instead of committing data directly to memory; all data is committed from the messaging bus in one batch once the job is complete.
- B. An asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an optimize job is executed toward a default of 1 GB.
- C. An asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an optimize job is executed toward a default of 128 MB.
- D. Before a Jobs cluster terminates, optimize is executed on all tables modified during the most recent job.
- E. Optimized writes use logical partitions instead of directory partitions; because partition boundaries are only represented in metadata, fewer small files are written.
Answer: C
Explanation:
This is the correct answer because it describes the behavior of Delta Lake Auto Compaction, which is a feature that automatically optimizes the layout of Delta Lake tables by coalescing small files into larger ones. Auto Compaction runs as an asynchronous job after a write to a table has succeeded and checks if files within a partition can be further compacted. If yes, it runs an optimize job with a default target file size of 128 MB. Auto Compaction only compacts files that have not been compacted previously. Verified Reference: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Auto Compaction for Delta Lake on Databricks" section.
"Auto compaction occurs after a write to a table has succeeded and runs synchronously on the cluster that has performed the write. Auto compaction only compacts files that haven't been compacted previously."
https://learn.microsoft.com/en-us/azure/databricks/delta/tune-file-size
NEW QUESTION # 87
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFramedf. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
Streaming DataFramedfhas the following schema:
"device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT"
Code block:
Choose the response that correctly fills in the blank within the code block to complete this task.
- A. "event_time"
- B. window("event_time", "10 minutes").alias("time")
- C. lag("event_time", "10 minutes").alias("time")
- D. window("event_time", "5 minutes").alias("time")
- E. to_interval("event_time", "5 minutes").alias("time")
Answer: D
Explanation:
This is the correct answer because the window function is used to group streaming data by time intervals. The window function takes two arguments: a time column and a window duration. The window duration specifies how long each window is, and must be a multiple of 1 second. In this case, the window duration is "5 minutes", which means each window will cover a non-overlapping five-minute interval. The window function also returns a struct column with two fields: start and end, which represent the start and end time of each window. The alias function is used to rename the struct column as "time". Verified References: [Databricks Certified Data Engineer Professional], under "Structured Streaming" section; Databricks Documentation, under "WINDOW" section.https://www.databricks.com/blog/2017/05/08/event-time-aggregation-watermarking-apache-sparks-struc
NEW QUESTION # 88
A data architect is designing a data model that works for both video-based machine learning work-loads and
highly audited batch ETL/ELT workloads.
Which of the following describes how using a data lakehouse can help the data architect meet the needs of
both workloads?
- A. A data lakehouse combines compute and storage for simple governance
- B. A data lakehouse requires very little data modeling
- C. A data lakehouse fully exists in the cloud
- D. A data lakehouse stores unstructured data and is ACID-compliant
- E. A data lakehouse provides autoscaling for compute clusters
Answer: D
NEW QUESTION # 89
......
Databricks-Certified-Professional-Data-Engineer Exam with Accurate Databricks Certified Professional Data Engineer Exam PDF Questions: https://pass4sure.dumps4pdf.com/Databricks-Certified-Professional-Data-Engineer-valid-braindumps.html